
Models don't have moats—products do 🏰
In the AI world, picks and shovels ⛏️ just help you dig a money pit


If you’ve been building software with AI, you’ve likely encountered two different camps of people regarding how generative models will evolve in the future:
Camp 1️⃣ believes companies with the most data and greatest computing resources will create the most powerful models, leading to a breakthrough in capabilities or "intelligence" (dare we say AGI) that other models won't have. Some folks here believe that the AI singularity is imminent in the next few years.
Camp 2️⃣ sees models as becoming commoditized, near-perfect substitutes, making it easy to switch toward cheaper and/or more accurate ones as they emerge. These folks also believe that there probably won’t be a silver bullet or easy path for AI systems to gain super-intelligence — building good AI products will require blood, sweat, and tears, just like building good products always has.
Spoiler: we’ve pitched our tent in camp 2.
The example of DeepSeek makes a compelling case for camp 2️⃣. Gemini 2.5’s greatly expanding capabilities1, as well as the slew of other new models that have been released, add to the smorgasbord. Meanwhile, OpenAI is losing money on every user while trying to maintain its first-mover advantage in user base.2
Since the original San Francisco gold rush in 1850, investors have seen the value of businesses building “picks and shovels”, preferring to bet on platforms and technologies rather than specific applications that they enable. But that value holds only if the platforms can maintain some sort of moat.
Unlike previous technological shifts like social media or the iPhone — platforms that benefitted from moats like network effects — AI model vendors have almost no moat whatsoever and customers will quickly switch to cheaper, faster, better competitors. Models aren’t moats, and infrastructure companies are getting their lunch eaten with every faster, better, and cheaper model.3

Is this a challenge if you’re building products that leverage AI? It sure is if you’re losing money on each pick or shovel you make, whiles competitors introduce shinier picks and cheaper shovels at a breakneck pace. But if you’re in the mining business — working in the application layer, it’s a huge opportunity. The true value of AI products will be unlocked the value-add beyond the model itself.
Think of a model like a car’s engine ⚙️. End users don’t buy engines; they buy cars 🏎️. If a better engine comes along, the car might become faster, lighter, or more fuel efficient — just like how swapping to a faster or cheaper language or image model improves performance of any AI-powered product.
At the same time, the skill of designing good cars won’t go away. Drivers still want a nice cabin, comfortable seats, and a pleasant driving experience. Users still want great UX, intuitive design, and a painless solution to their problem — yet today, almost everything still looks like a chatbot. The ability to create good products is still in vogue, still as difficult as ever, and just amplifies the power of a fantastic engine.
So if camp 2️⃣ best represents what’s happening, what’s the upshot?
Create your AI product to take advantage of the latest and greatest models instead of committing to any specific one, and it will only get better and more efficient over time. In the long run, models (text, image, or multimodal) will all do pretty much the same thing.
To do that, leverage consistent output on well-defined tasks to build pipelines and systems, rather than relying on one-shot prompts that do it all. Training models, even when it’s as simple as prompting or fine-tuning LLMs, still requires data, validation, and most importantly — solid problem formulations. 4
This work is easier said than done, and requires the synthesis of AI, engineering, product, and design thinking. On our team, the combination of strong technical intuition with expert product design has unlocked some unique and magical interfaces. We’re going to write about some of those learnings in a future post!
Most importantly, don’t lose sight of building great products, which are hard to find and still very much in demand. When users love your product and there aren’t any alternatives in sight, that’s a moat you can count on.
Over here at Parsnip, we’re building an AI-powered knowledge graph builder, setting the stage for a better way to learn — an AI tutor that is aware of what you’ve learned and where you can go next. We see incredible potential to deploy this technology in the areas of our lives for which there are no schools. Most of our work is behind the scenes for now, but here’s a sneak peek:
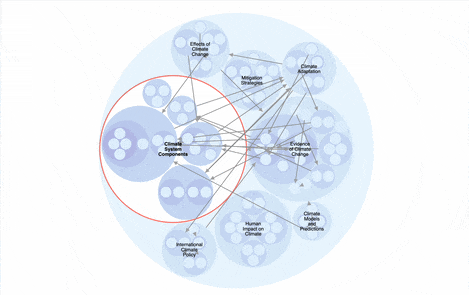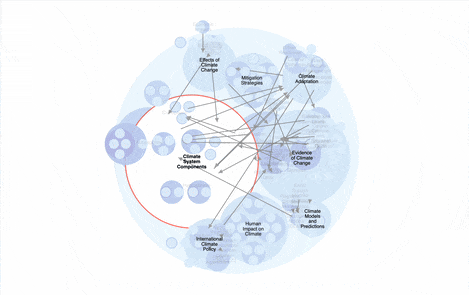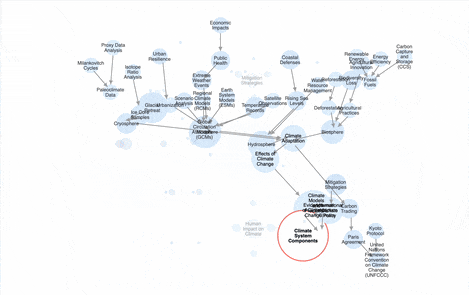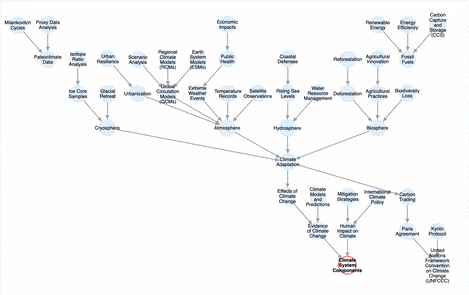
In meeting many other founders who are building AI tools to teach new skills, we’ve found that they all seem to have the same two problems:
organizing things users can learn, or skills they can do, in an interpretable way, and
automated and scalable, yet consistent and reliable content creation to transfer and teach those knowledge and skills.
If you’re building something that helps people level up, learn, or be coached and are finding that it’s unnecessarily laborious to do one or both of the above, please reach out! We might have some powerful ways to help.
Gemini 2.5 currently outperforms competitive models on a variety of benchmarks. Though, a new front-runner will likely emerge shortly.
As of April 2025, Gemini’s 350M MAUs (buoyed by the release of 2.5) have made significant progress against ChatGPTs 600M MAUs.
A possible analogy here: all the dollars poured into model training are like the prodigious laying of fiber-optic cable during the dot-com bubble. Those telecom companies lost their money, but we all got to reap the benefits for decades afterward.
One way we think of LLMs is that they’re machine learning models that no longer require highly technical or PhD-level expertise to work with. They can be trained with natural language, operate on sparser datasets, and generalize better. But they still need data to be trained, evaluated, and improved in a systematic way.
 | A guest post by
|
Amazing! The best part of this post was the driving experience vs. engine type analogy. Most people want a pleasant driving experience, not just a powerful engine. A good engine only enhances that experience. I wish more founders thought this way. I believe we’re currently in an AI bubble, and the companies that will last are the ones focused on building products that truly deliver outcomes and long-term value.
very good take