
What we've learned about learning 💡
How AI can scale up effective pedagogy and help solve the 2-sigma problem




Much of our recent work has focused on developing an AI-powered knowledge management and learning platform. In order to build this, however, we first needed to gain a deep understanding of how people learn. None of us began this work as experts in education, but we’ve been fortunate to work with collaborators who introduced us to best practices in pedagogy—allowing us to then decide, in this new AI-centric world, what remains relevant and what may become obsolete.
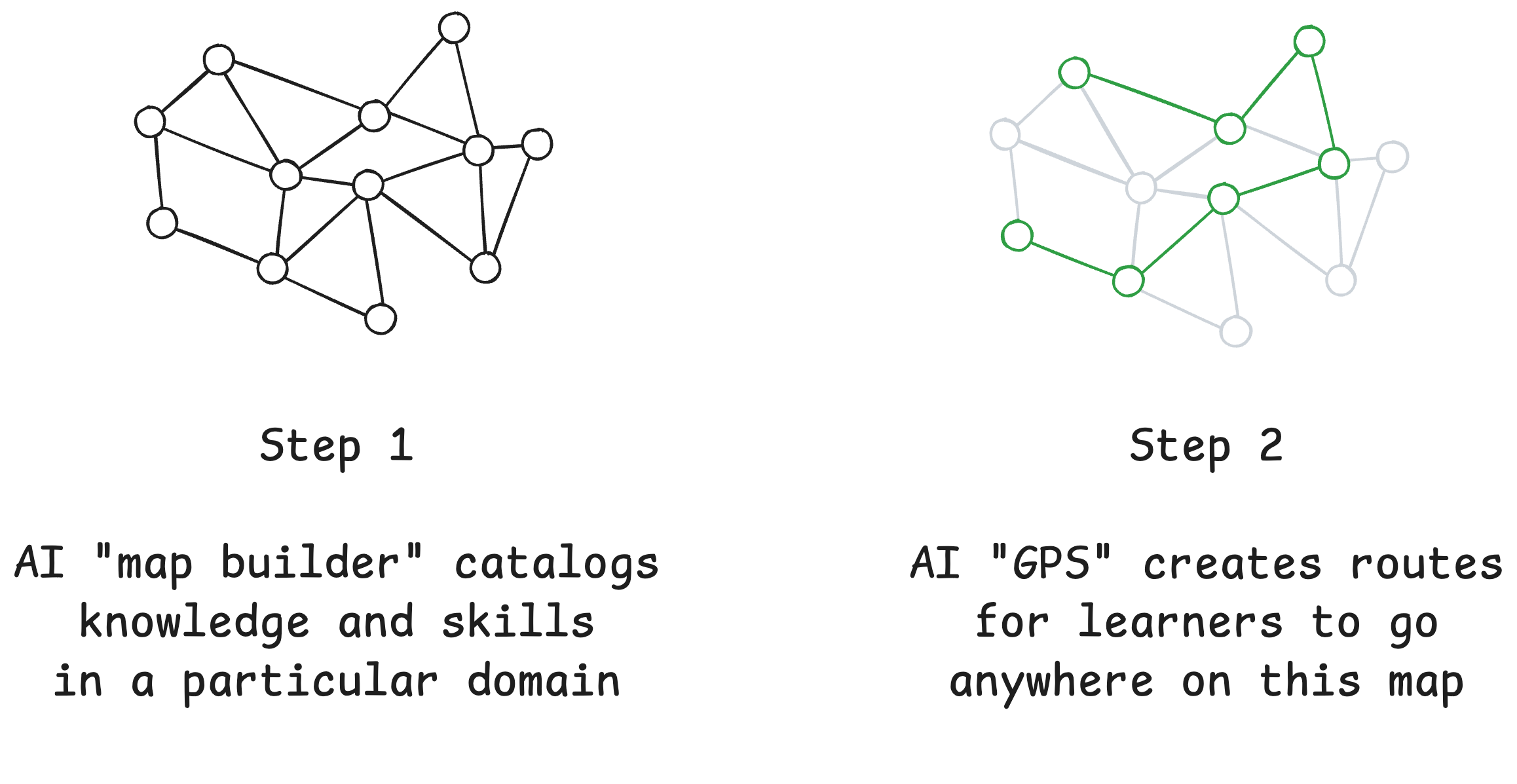
As a refresher, the key idea behind our approach to personalized learning is to first build a map of knowledge/skills, then create a personalized “GPS” for this map. Thus, our system needs to catalogue what to teach, decide when and how to teach it, and finally measure whether it stuck. We want to share some key ideas from pedagogy and education that have shaped our thinking and will inevitably be reshaped as we integrate them with AI.
Please share this post and leave your thoughts below!
Bloom’s taxonomies
A core insight for how we can organize and measure learning is that granular units or “atoms” can be used to represent (1) knowledge that a person knows and (2) skills they can execute.
Our inspiration here came from Benjamin Bloom (the same Bloom of the eponymous two sigma problem), whose seminal work on frameworks in education included various taxonomies of what people actually learn. His cognitive taxonomy shows how we might start from lower-order memorization of knowledge and build up to higher-order critical thinking skills:
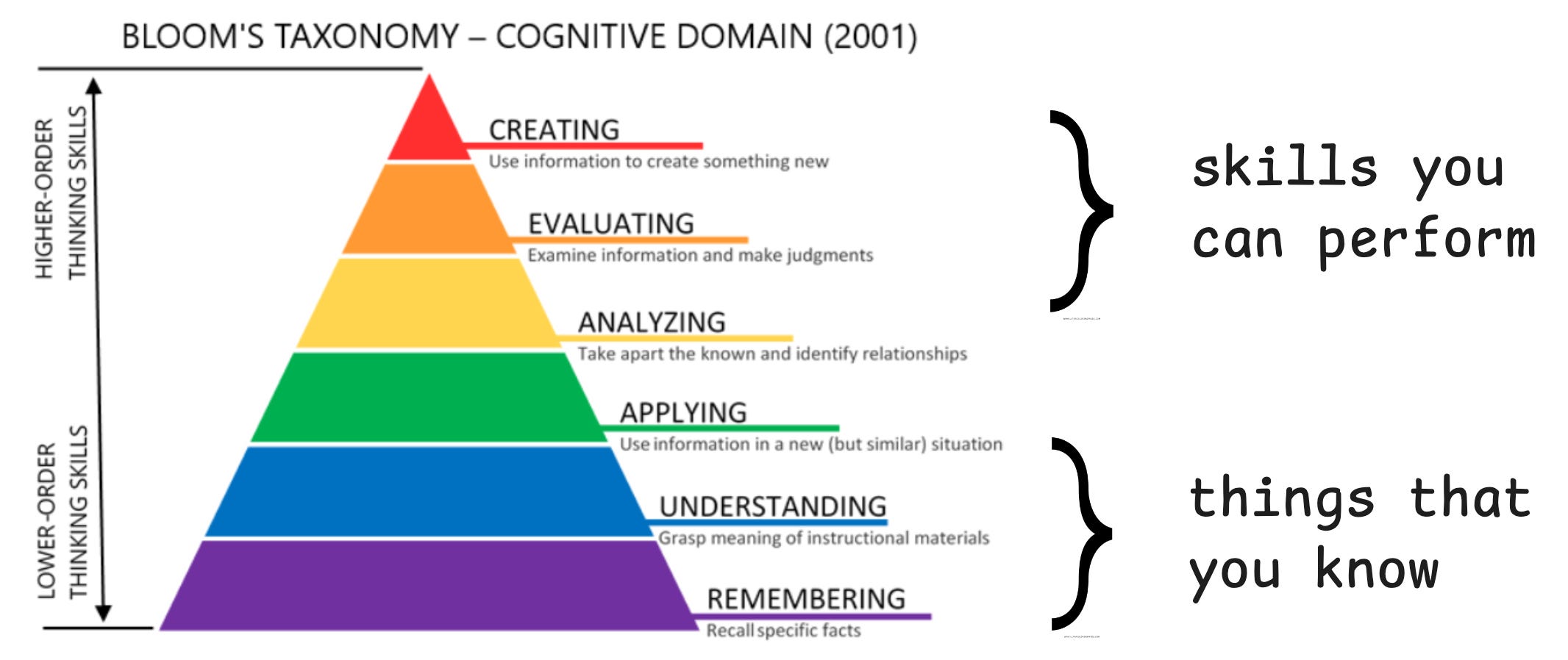
An important insight here is that you need the lower layers as foundations in order to build up to the higher ones. You can’t make good guacamole unless you know what a ripe avocado looks like, and you can’t improvise flavor combinations in food without first developing a sense of what flavors go well together. Moreover, mastering these higher-level skills requires practice and doing, not just memorization and rote learning.
As part of Bloom’s prolific work, he actually proposed several taxonomies—beyond the cognitive domain, he also modeled how we learn psychomotor and affective skills. In modeling the cooking skill tree, we’ve revised and expanded Bloom’s ideas to create a framework that encompasses not only cognitive tasks, but also physical skills in the real world.
Right now, there’s significant—and valid—concern, from K-12 to universities, that AI is disrupting the status quo in education. From our perspective, however, the threat from AI isn’t to learning in general, but to the way that our current educational system prioritizes the lower levels of Bloom’s taxonomy: remembering, understanding, and basic applications of knowledge. These are things that LLMs are quite good at, and it’s also what dominates many curricula, hence the alarm.
Yet, AI permeating education might actually be a good thing in the long run—if it shifts focus toward and amplifies our educational system on the higher-order skills: critical thinking, analysis, synthesis, and creation of novel things.1 In an ideal future world, students could spend less time proving themselves with drills and facts and instead advance more quickly in mastery to creating from what they’ve learned—which incidentally will be difficult for AI to automate, but is what matters in the real world. Moreover, there’s a huge opportunity to teach many real-world skills that aren’t actually served by our educational system.2
So, while AI’s disruption of education is quite uncomfortable for educational institutions in the short term, it may ultimately, in the long run, result in something hugely beneficial for human education at large.3
Backward design
You may have experienced a high school or university course that sequentially followed a textbook, then tested your knowledge at various points. This is in fact quite common: many instructors will simply present a sequence of content, shaped by the materials readily available to them, without considering whether that sequence is coherent, self-reinforcing, and builds up to the skills students should take away from the course.
In college and graduate school, I learned that many professors even create their lectures just-in-time—that is, by assembling materials in the hours before each class! When we create content in the moment, led by existing material, it’s easy to lose sight of how to build up to a final outcome. Making matters worse, many universities will staple together new programs using existing courses, with minimal coordination between instructors. This process provides few guarantees about what skills graduates will be able to take with them.
Instead of starting with content, backward design starts with the outcomes: at the end of this course or program, what should the learner be able to do? From there, working backwards allows us to derive the skills, sub-skills, and foundational knowledge they’ll need to accomplish these goals. Backward design enforces intentionality in teaching, and it’s relevant to any area of learning—for example, to make scrambled eggs, you’ll need to learn how to whisk an egg, control the heat on your stove, and fold the eggs while managing heat.
You can probably see where this is going: in Bloom’s taxonomy, you can start from the higher-level skills and work backward to derive the lower-level skills. If your goal is at the top of the pyramid—say, “Improvise dishes of Mexican cuisine from what’s in your fridge”—then you can break this into parts, defining the foundational concepts and abilities required to support it. This essentially creates a “dependency graph” or skill tree4 specifying the progression of knowledge and abilities needed to achieve the final goal.
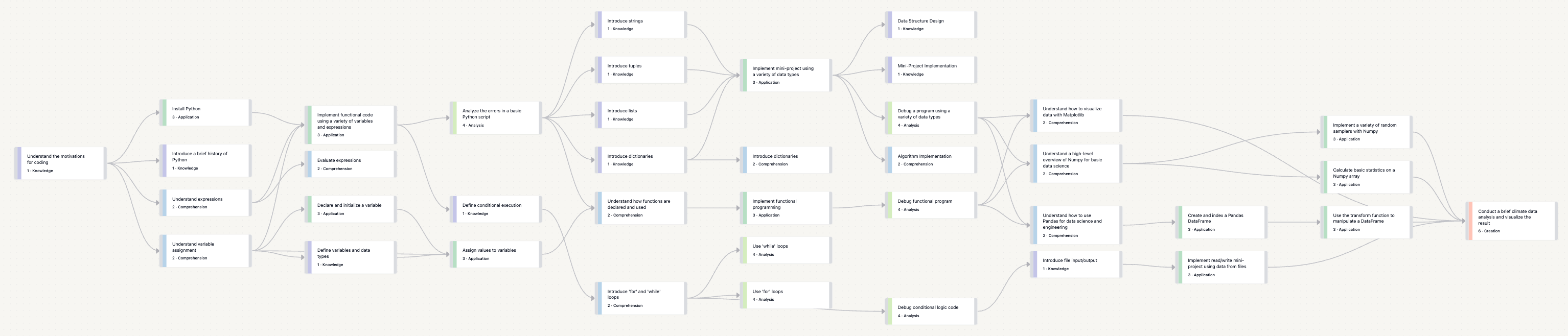
A skill tree like this, while incredibly useful for both directing the learning itself and measuring progression through it, has been a largely implicit construct in almost all forms of learning. And that’s not an indictment of teachers—it would be a herculean effort to construct by hand, yet not very useful without being able to leverage its structure for teaching. Yet, when AI can help us rapidly build this skill tree, we can finally address a critical part of the 2-sigma problem.
Mastery learning
You may recall that mastery learning is one of two key aspects of Bloom’s 2-sigma observation. Put simply, it’s the idea that students need to “master” pre-requisite skills/knowledge before moving on to more advanced topics—or, that you really should be able to control the heat on your stove before trying to scramble an egg. This has also been referred to as competency-based education.
It just so happens that this skill tree, defined in terms of observable objectives, is an ideal representation for facilitating mastery learning. A key distinction of our approach is that this graph doesn’t live in a vacuum, but acts as a form of RAG5 for source material—so that AI pipelines can create relevant, accurate content to help learners “acquire” objectives in this graph. Then, using appropriate assessments to measure progress, we can see how students are doing on those milestones.
It’s now common to think of AI in education as learning that happens primarily through a LLM-powered chat interface. But, that’s only scratching the surface of what’s possible. This AI-powered skill tree, backed by authoritative input sources, is far more powerful:
It allows the instructor or an expert in the subject to select relevant knowledge to teach, and specify the right process to progress through it. As a result, students engage with content that’s relevant, accurate, and free of hallucinations.
The student’s learning journey becomes explicit and visible, making it clear where they’ve been and where they can go, and empowering the instructor to assist along the way.
The AI system can respond to what a learner knows and doesn’t yet know, personalizing their journey and even allowing learners to go on different paths.
Powerful as it is, the skill tree by itself is still just technology. The real impact of this approach gets realized only when it’s paired with an equally well-designed interface for learners—which is why we’re very excited for Parsnip to be one of the first applications of this new system, allowing us to both create learning paths through the skill tree, and also dynamically connect them to recipes.
Spaced repetition and IRMA
The final piece of the puzzle is to make sure that learners are indeed exposed to concepts, knowledge, and skills enough times to have really mastered them. Spaced repetition, popularized by flashcard systems like Anki, greatly improves memorization by prompting recall at increasingly spaced intervals.
But this kind of “memorization on steroids” is mostly helpful for the low-level cognitive tasks on the Bloom cognitive taxonomy: remembering and understanding names, dates, formulas, vocabulary — the exact things we believe will become less central to education in the age of AI.
Enter spaced repetition’s bigger brother, IRMA (Introduce, Reinforce, Master, Assess). This is a less well known but more general framework from curriculum design. Unlike spaced repetition, which focuses on memorization, IRMA is a model that accounts for progression from knowledge, to skills, to more advanced skills. It ensures that important ideas aren’t just introduced, but revisited in deeper contexts—moving from “I’ve heard of this” to “I understand this” to “I know how to do this”.
Explicitly accounting for the stages of IRMA is pedagogically invaluable: it helps track how often and how deeply a concept is revisited, and whether that exposure is sufficient for what we’re expecting students to learn. In other words, it can be used to verify that backwards design and mastery learning are working as intended. Yet, it’s very time-consuming—so, as with backwards design, it’s rarely done explicitly, making it a perfect place for AI to step in. Using our skill tree, it becomes straightforward to analyze how well a course design is meeting its intended goals.
We’re still learning…
None of these ideas are new, having been refined by educators over decades. But in the process of building an AI learning system from first principles, we’ve had a chance to see how they interconnect—and far from being rendered irrelevant by AI, may become more useful than ever when integrated into a scalable, holistic learning platform that’s possible with new technology.
Our work has raised some big questions, too:
Traditional institutional teaching roles include curriculum designers, instructional designers, and the instructors themselves. How do these responsibilities change with AI as part of the process, replacing and accelerating pieces of this work?
This kind of scalable, ubiquitous, pedagogical design makes explicit what has often been invisible for teachers. Now that everything can be seen in an analytical, data-driven system, how does it feel to educators? How can we incorporate this into existing teaching workflows?
More generally, how do we really empower educators with AI tools, rather than exacerbating fear about how AI is transforming education?
If you're an educator, curriculum designer, learning scientist, or working in this space, we’d love your thoughts. What did we get right? What are we missing?
AI isn’t good at these tasks—and in our opinion, may never be using current LLM architectures. This article makes a great case for why these fundamental limitations exist.
Some of the domains we’re particularly excited about for future versions of Parsnip involve broadly applicable real life skills that aren’t taught in school. Beyond cooking, these include relationships, parenting, management, social-emotional skills, health & fitness, and personal finance.
It’s now common to see AI bans in different educational contexts, but the ubiquity of this technology is inevitable. So, maybe it’s worth asking: how could AI enhance how we learn, rather than becoming a crutch that will sabotage our ability to read, write, and think critically?
More precisely, this is a directed acyclic graph (DAG). It’s often used to model situations where certain things need to be done before others. Another common example: dependency management in software projects.
Retrieval-augmented generation: essentially, allowing an LLM to make use of information that isn’t in its training data.
I really enjoyed this perspective on how AI is reshaping Bloom’s taxonomy. I agree that AI challenges the need for students to focus on lower-order thinking, but I also think those foundational skills still matter. We do not need to see them as isolated steps; we can see them as connected layers within a larger understanding system.
If we look at Bloom’s taxonomy less as a pyramid and more as a network or skill tree, the lower levels become the soil that nourishes higher-order thinking. In design, for example, the ability to create something novel often comes from a deep, almost intuitive grasp of foundational principles like composition, spacing, or visual rhythm. Remembering and understanding aren’t less valuable, but they become the scaffolding that allows meaningful creation to emerge.
Maybe the future of learning isn’t about removing lower-order skills but merging them into a more connected learning model. A model where knowledge, practice, and creation continually reinforce each other.